| |
|
|
| |
Ongoing research: The Conserved Domain Database (CDD), as well as the conserved domain architecture annotated on proteins by SPARCLE, continue to evolve as new data become available and as research progresses. Therefore, the live web page views might differ from the illustration above.
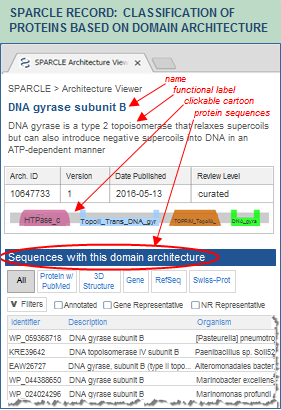
For example, in January 2017, the protein sequence NP_387887 was initially annotated with architecture ID 10647733 (as shown in the illustration). That architecture is named "DNA gyrase subunit B" and includes four distinct conserved domains.
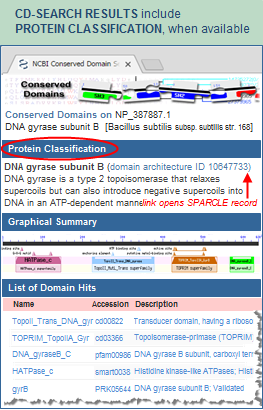
In March 2017, when a new build of CDD/SPARCLE was released, the conserved domain architecture annotation for NP_387887 was revised to architecture ID 11481348, which is a multi-domain that encompasses the four original conserved domains, and which can be seen in the current CD-Search results for NP_387887. That architecture has a more specific and precise name, "type IIA DNA topoisomerase subunit B," and reflects the full length protein model.
To see the four distinct conserved domains that compose the multi-domain, simply change the CD-Search display option on the live CD-Search results for NP_387887 from "Concise Results" to "Full Results" (using the "View" menu near the upper right hand corner of the CD-Search results page). The Full Results display will show the four conserved domains that compose the multi-domain.
As the available data and understanding of conserved domain architectures continue to evolve, the domain architectures that are annotated on proteins may evolve as well, as shown in this example. Comments about the data are welcome and can be sent to the NCBI Support Center/Help Desk, which is accessible as a link in the footer of NCBI web pages.
|
|
| |
![Step 1 in searching the SPARCLE database by keyword: Enter the desired search terms in the query box, adding curated[ReviewLevel], if desired, to limit results to curated domain architectures. Click on this graphic to open the SPARCLE home and input your own search terms.](images/entrez_sparcle_step1_home_page_search_for_chloride_channel_curated_reviewlevel.png)
![Step 2 in searching the SPARCLE database by keyword: View the search results and click on the architecture ID of any domain architecture of interest to open its summary page. Click on this graphic to open the results of a SPARCLE search for chloride channel AND curated[ReviewLevel].](images/entrez_sparcle_step2_search_results_chloride_channel_curated_reviewlevel.png)